5分钟阅读
RAG已死?不,它在智能体时代完成了进化

RAG已死?不,它在智能体时代完成了进化
译者按
你可能听过“AI现在能记住上百万字,不用查资料了”,所以有人说“RAG这技术凉了”——但事实是,RAG没凉,反而变得更聪明了!
简单说,RAG以前就是AI的“搜索引擎”,不管啥问题都先搜一堆资料给AI参考。后来大模型能记住更多内容,大家就觉得“不用搜了,直接让AI凭记忆回答就行”。但实际用下来发现:记太多东西又贵又慢(好比开会请10个人却只问一个人问题),而且图片、图表这些内容,大模型根本记不住也看不懂,还得靠“搜”;更重要的是,现在的RAG学会“偷懒”了——先判断要不要搜、该搜啥、去哪搜,不做无用功,比以前精准多了。
这篇文章其实就是想告诉大家:AI查资料的技术没被淘汰,反而进化成了“智能管家”,会根据需求精准发力。以后咱们用AI处理工作、查信息,会更省钱、更快、更准,尤其是遇到带图的专业文档时,这技术更是离不开~
核心摘要
- 长上下文并未淘汰检索技术。更大的上下文窗口会增加成本和噪声,而检索能聚焦关键信息。此外,对于典型工作负载,RAG比长上下文方案便宜8-82倍,且延迟更低。
- 多模态至关重要:grep和词法搜索在代码场景表现出色,但对图表和图形完全失效。企业内容需要语义+视觉感知的检索与重排能力。
- 条件检索优于自动检索:2025年的RAG是模块化的,需决策是否检索、检索内容、检索来源及检索方式,而非盲目检索。这意味着元数据至关重要,需投入离线预计算来描述数据集,运行时决策依赖对现有资源的清晰认知。
- 精细化评估:阶段式指标必不可少。仅依赖端到端评估会阻碍系统优化。
智能体时代并未让检索技术过时,反而让智能检索成为核心需求。
本文基于Amélie Chatelain在Weights & Biases 2025 Fully Connected大会上的演讲内容。

自2023年底以来,机器学习社区多次宣称检索增强生成(RAG)已死。随着大型语言模型(LLM)不断推出更大的上下文窗口——Anthropic Claude的10万token、Google Gemini的100万token乃至更高——一种观点逐渐占据上风:“既然能把所有内容都塞进上下文,何必还要检索?”
但到了2025年的今天,检索技术非但没有消亡,反而愈发活跃。它不再是2023年那种简单的流水线式方案,而是智能体系统中一套复杂、可控的注意力分配机制。本文将探讨RAG为何没有消亡,反而不断成熟,以及LightOn团队为何坚信强大的检索流水线是AI系统的核心支柱。
RAG的炒作周期:时间线
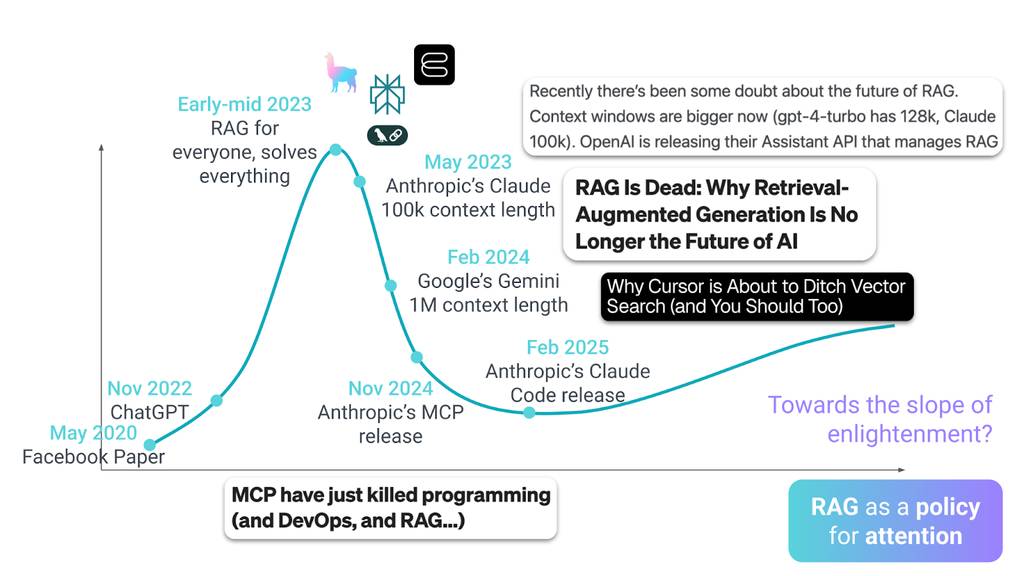
时间回到2020年5月。当全世界还在应对疫情封锁时,Facebook人工智能研究院发表了一篇论文,定义了未来五年企业AI的发展方向:RAG技术。这种方法能让语言模型在不重新训练的情况下获取外部知识。随后在2022年11月,ChatGPT横空出世。一夜之间,所有人都开始关注大型语言模型和生成式AI,市场的闸门彻底打开。
到2023年初,RAG进入了期望膨胀期峰值。风险投资大量涌入,初创公司如雨后春笋般涌现,每家都承诺RAG能解决模型幻觉、普及企业知识、革新工作方式。向量数据库成为必备基础设施,当时的叙事简单而诱人:人人可用的RAG,能解决所有问题。
但风暴很快来临。2023年5月,Anthropic发布了支持10万token上下文的Claude。RAG的“铠甲”首次出现裂痕,质疑的声音开始出现:“如果模型能将整个代码库存入内存,还有必要检索吗?”
2024年2月,转折点到来。Google发布了支持100万token上下文的Gemini,这相当于《指环王》三部曲的总文字量。科技圈陷入热议,大量博客文章宣称:“RAG已死:为何检索增强生成不再是AI的未来”。其逻辑看似无懈可击:既然能把所有内容都塞进上下文,何必构建复杂的检索流水线?
“RAG已死”的论调持续发酵。2024年11月,Anthropic推出模型上下文协议(MCP),标题再次宣称“MCP杀死了RAG”——却忽略了MCP本质上就是一种检索机制。RAG中的“R”(检索)简直欲哭无泪。
2025年2月,许多人认为RAG的棺材钉终于敲下。Claude Code发布,采用grep和文件通配符进行代码导航,无需向量搜索。这与Cursor等其他智能代码工具的索引检索方案形成鲜明对比。行业共识似乎达成:RAG只是2023年的短暂潮流,如今已被更优方案取代。
但事实是,这些所谓的“RAG杀手”从未真正淘汰检索技术——它们只是推动了检索的进化。接下来我们详细分析。
核心问题:长上下文真的杀死了RAG吗?
要回答这个问题,我们需要审视“把所有内容塞进上下文窗口”的真实成本——无论是经济成本还是性能成本。
会议类比:长上下文如同低效沟通
想象一个熟悉的场景:有人有一个简单问题,但他没有找对人询问,而是召集了10人开会。结果是什么?
10人参加30分钟会议的成本约为750美元,而直接询问相关专家仅需75美元。长上下文的运作逻辑与此相同:当只需几千token就能承载答案时,却引入百万token,不仅会让信号淹没在噪声中,还会产生高额成本。而专注的RAG流水线,就相当于直接询问专家。
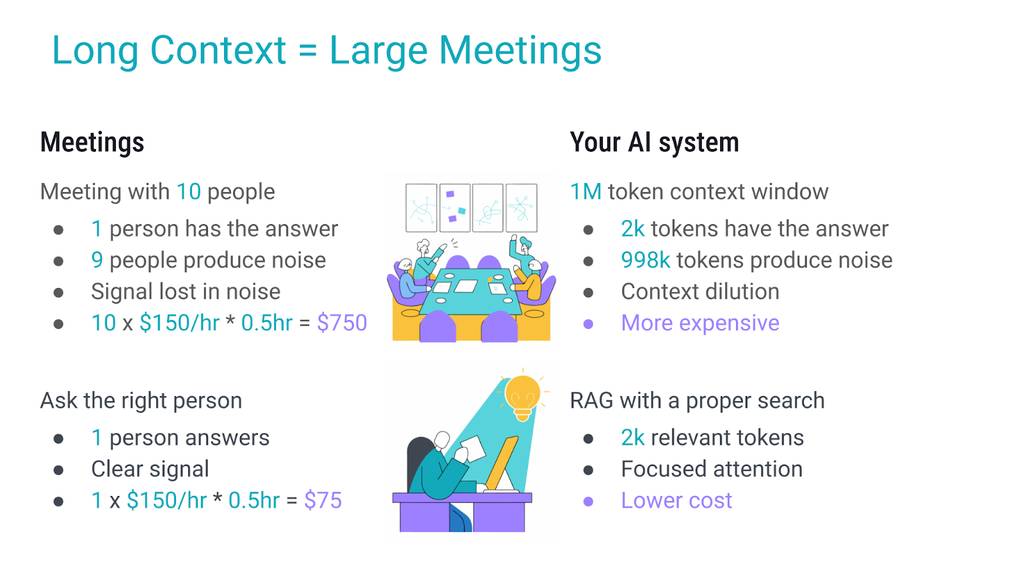
长上下文就像大型会议:低效、缓慢且昂贵。
长上下文的真实经济成本
在准备演讲时,我试图寻找“全量塞入上下文”与“最小化检索”的具体成本对比数据,但一无所获。因此,我开发了一个长上下文计算器。你可以通过Streamlit体验(链接),代码已开源在GitHub(链接),可根据自身业务场景调整参数。
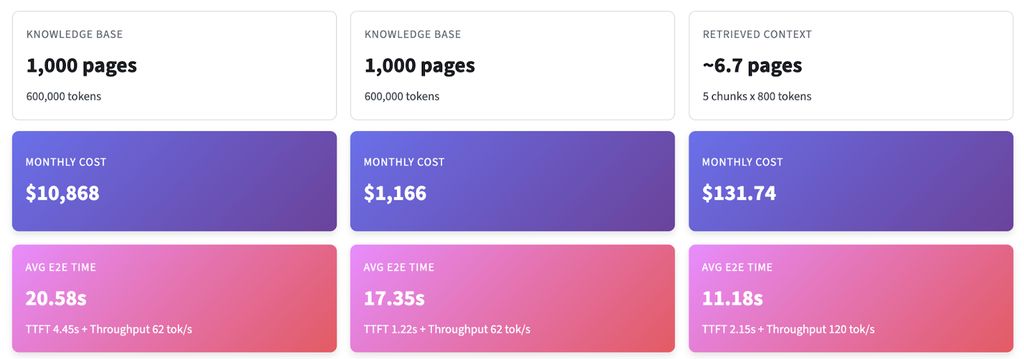
以下是具体数据:针对1000页的知识库(约60万token),假设每天100次查询。
核心结论:即使启用缓存,长上下文工作流仍会增加复杂性,且在延迟和价格上处于劣势。在实际场景中,检索约5个目标片段的方案仍便宜一个数量级——因为生成过程主导了端到端的耗时。
长上下文的幻觉:容量≠理解能力
认为100万token能解决所有问题,本质上是一种误解。
首先,我们要明确100万token的实际规模:看似庞大,但普通的纯文本代码库就能轻松突破这个限制。
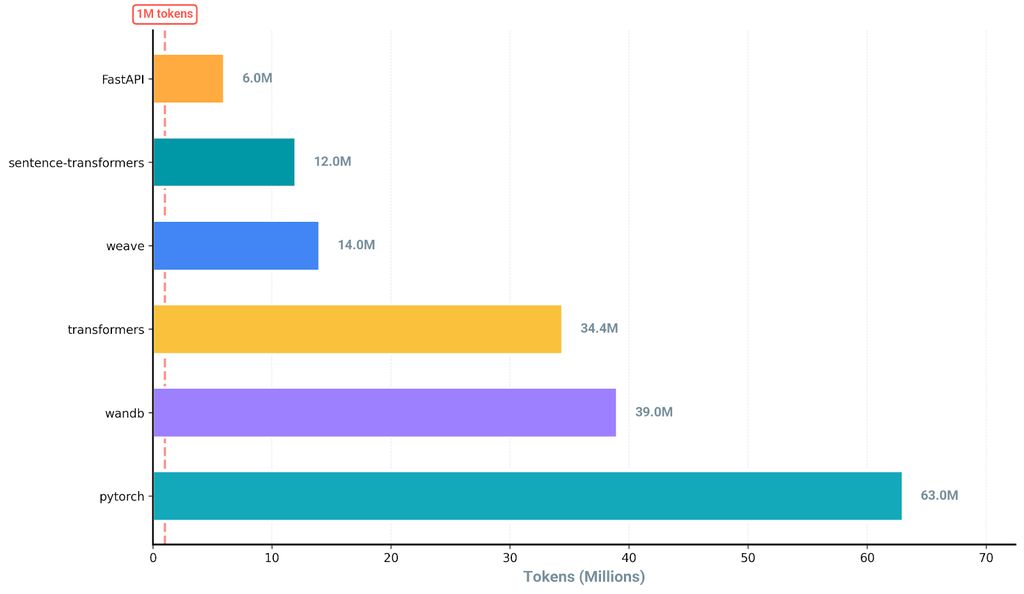
GitHub上热门机器学习仓库的大致token数(通过工具计算)。
多模态内容会让情况更糟:一张图片的token成本约为1000-1500。预算会快速耗尽。为了更直观理解,我们用一个有趣的标尺:《指环王》(数据来自Antoine Chaffin)。《魔戒同盟》约25万token,三部曲+附录约70万token,而电影(非加长版,2小时58分钟,24帧/秒)若简单按帧分词,约需1.71亿“图像token”。可见,100万token并非想象中那样无限。

《魔戒同盟》书籍(紫色)、《指环王》三部曲书籍(蓝色)与《魔戒同盟》电影(非加长版)的token量可视化对比。
此外,研究反复表明,随着上下文长度增加,模型性能会下降。基准测试显示,性能取决于模型类型、模态,甚至答案在上下文中的位置——这就是经典的“中间遗忘”现象。
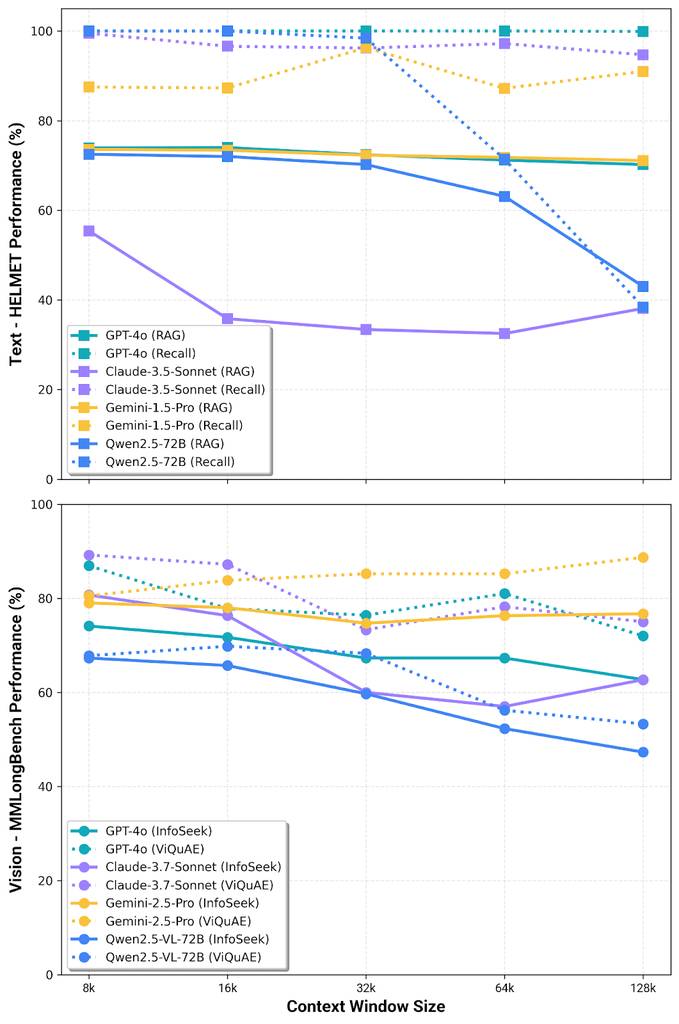
性能会因模型、模态甚至答案在上下文的位置而大幅波动。当我们将整个知识库塞入上下文时,完全无法控制答案的位置。数据来自HELMET基准测试(上)和MMLongBench(下)。
这并非暂时的工程问题,而是规模化下的注意力稀释。更多上下文不代表更好的理解能力,反而意味着需要过滤更多噪声。
为何grep不够用:多模态挑战
Claude Code基于grep的词法检索取得成功,引发了一个问题:语义检索是否还有必要?答案完全取决于你的内容类型。
grep的适用场景
grep在以下场景表现出色:
- 术语一致的纯文本文档
- 结构清晰、标识符有意义的代码
- 精确字符串匹配即可满足需求的内容
Claude Code正是面向这类场景:代码库中的函数名、变量名和注释都是为人类可读性和grep检索设计的。
可以把grep比作给同事发私信:发送请求、等待回复,必要时扩大搜索范围。它无需索引,易于部署——但对于某些场景,其速度和成本可能不如向量数据库(再次参考我的计算器)。
但当答案藏在图表中时,grep就失效了。
grep的失效场景:视觉化现实
但企业知识并非都像代码那样结构化。考虑以下查询:
查询:“哪些元件位于套管悬挂器上方?”
文档:油气操作手册中的技术 diagrams,展示了井身结构及带视觉标签的空间关系。

你的文档可能并不适合grep检索。
grep无法做到:
- 解析图像中的空间关系
- 理解图表中的视觉层级
- 从图表、图形或示意图中提取信息
- 理解视觉语境中“上方”的语义含义
你无法用grep检索图表。这就是多模态RAG的核心价值:结合视觉-语言模型进行检索,同时理解文本和视觉内容的语义。
生产级系统需要:
- 支持文本+图像的多模态嵌入模型
- 具备视觉理解能力的重排器(如MonoQwen),能理解视觉上下文,确保提供给LLM的内容精准无误
智能检索:智能体时代的RAG
2023年到2025年的最大转变是:RAG不再是“固定检索k个片段”,而是一套决策体系——有意识地分配注意力。
四大决策节点
现代检索系统在每个阶段都会做出条件决策:
1. 是否检索:工具路由(是否需要开会?)
并非所有查询都需要检索。智能体应基于以下因素决策:
- 查询类型:是事实查询、总结查询还是其他类型?
- 时效性要求:现有知识是否足够?
- 安全/隐私限制:是否需要联网查询?
示例:
- “2+2等于多少?”→ 直接回答,无需检索
- “我们第三季度的营收数据是多少?”→ 需要检索企业知识库
- “巴黎本周末的天气如何?”→ 时效性查询,需联网检索
📊 评估方式:通过与理想路由的F1分数对比,同时跟踪延迟和成本,避免为简单查询过度调用工具。
2. 检索内容:工具参数构建(会议议程是什么?)
若需要检索,需结合用户上下文(角色、部门、访问权限、历史数据等)和领域知识(通过实体识别、查询扩展构建过滤器等),构建最优查询。
示例转化:
{
"query": "LightOn第三季度报告的核心数据是什么?",
"filters": {
"time_range": {
"start": "2025-07-01",
"end": "2025-09-30"
},
"document_type": "report",
"department": "finance"
}
}
📊 评估方式:通过对比有无查询改写的检索召回率/精确率差异,以及过滤器提取准确率,评估系统的查询理解能力。
3. 检索来源与方式:检索策略(邀请谁参加会议?谁先发言?)
选择合适的检索策略:代码用词法检索,散文用语义/混合检索,若答案在图表中则用多模态检索;利用丰富的元数据和离线预计算,选择正确的数据集,避免在查询时让用户等待。
示例场景:
- 财务报告查询→ 使用财务文档数据集,结合视觉检索捕捉报告中的各类图表
- 提及特定代码函数→ 使用代码库数据集
- 模糊查询→ 检索多个数据集,对结果进行重排合并
✨ 关键洞察:若没有关于数据集内容的丰富元数据,就无法确定检索哪个数据集、使用哪种策略。这需要离线预计算——提前投入资源描述数据集特征,确保运行时决策快速准确。
📊 评估方式:分别测量重排前后的检索指标,评估检索和重排能力。
4. 生成答案:基于精准上下文作答(撰写准确有用的会议纪要)
检索和重排后,基于最小化的可靠上下文生成答案。
📊 评估方式:从答案与来源的一致性、任务准确性等维度评估生成质量。
核心要点:这应是最后的评估指标,而非唯一指标。为什么?
评估:定位复杂系统中的故障点
向条件化、多阶段检索的转变带来了一个关键挑战:当智能体失效时,问题出在哪个环节?
故障会级联传递。若工具路由错误,后续所有环节都会失效;若查询构建不佳,检索会得到无关文档。因此,评估必须隔离每个阶段。
只有通过这种精细化的可见性,才能:
- 确定需要优化的组件
- 区分故障是系统性问题还是边缘案例
- 在每个阶段优化成本与质量的平衡
- 基于数据决策模型选择、提示策略和系统架构
若跳过精细化评估,仅测量最终答案质量,无异于自寻死路。你会得到一个无法正常工作的流水线,却找不到问题根源。
结论:RAG没有消亡,而是不断成长

过去两年并未淘汰检索技术,而是迫使RAG走向成熟。如今的RAG是一种“有意识的注意力分配”:决策是否检索;若需要,决策检索内容、来源和方式;保持上下文精简;全面测量每个环节。换句话说,不要再“为了以防万一”召开大型会议,而是找对专家、只带必要材料、保持沟通高效——这就是智能体时代的RAG。
这种进化与从流水线到智能体的整体行业转变相契合。核心洞察包括:
- 决策是否检索:知道何时无需开会——并非所有查询都需要外部上下文。
- 智能路由:找专家而非整个部门——基于元数据的定向检索优于穷举搜索。
- 全面测量:跟踪每个决策节点——精细化评估对复杂系统至关重要。
未来并非“RAG与长上下文对立”,而是智能系统根据每个查询的具体需求,实时决策如何策略性地结合两者。
RAG已死,RAG永生。
想了解LightOn如何构建“先思考再检索”的检索系统?
探索我们在智能检索领域的最新研究和产品,或联系我们观看演示 👉 联系我们!
更多 AI 前沿技术与设计灵感,欢迎关注「设计小站」公众号(ID:sjxz00),一起探索科技与设计的融合创新。
原文:https://www.lighton.ai/lighton-blogs/rag-is-dead-long-live-rag-retrieval-in-the-age-of-agents