5分钟阅读
注意看!从图像到3D,从平面到分层:两项将重塑设计流程的AI技术

从图像到3D,从平面到分层:两项将重塑设计流程的AI技术
前言
对于设计师而言,AI正从简单的“辅助工具”演变为能够理解并重构视觉内容的“创意伙伴”。今天,我们聚焦两项刚刚发布、极具潜力的技术:一项能将你的二维灵感瞬间转化为高保真3D资产,另一项则能像Photoshop一样,智能地将图片“拆解”成可独立编辑的图层。它们将如何改变你的工作流?一起来看看。
一、微软发布 T-RELLIS .2:图像秒变高保真3D模型
想象一下,上传一张产品草图或概念图,几秒到一分钟内,就能获得一个带有逼真PBR材质的3D模型,并且可以处理任意复杂的结构。微软研究院开源的T-RELLIS .2模型,正在将这个想象变为现实。
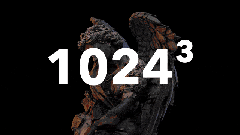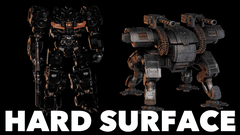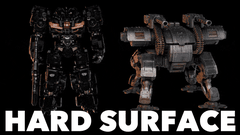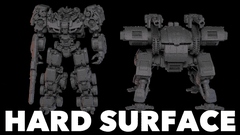



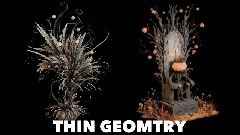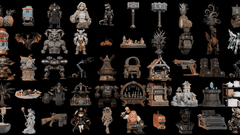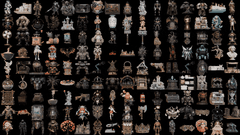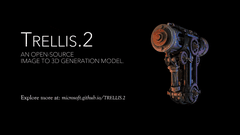
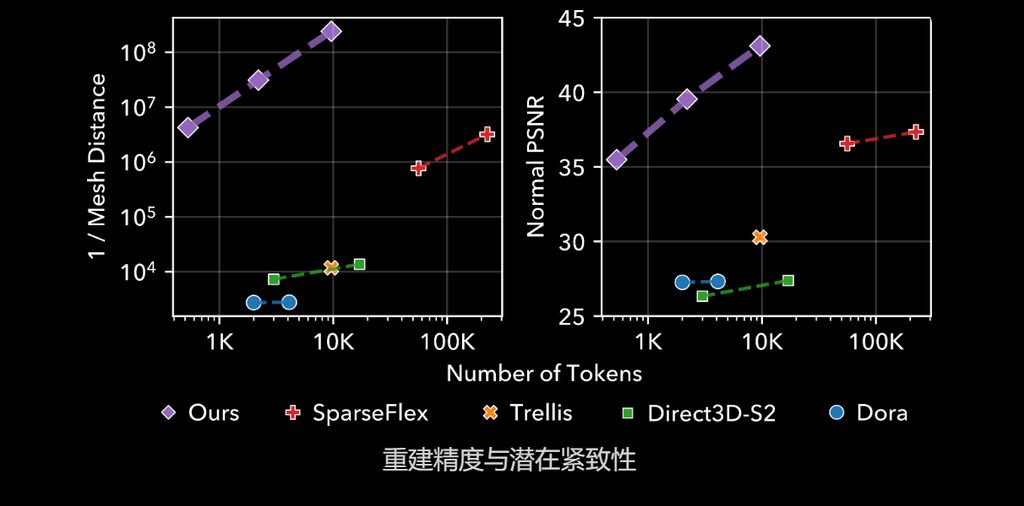
核心简介:这是一个拥有40亿参数的开源图像转3D模型。其核心是一种原生且紧凑的结构化潜在变量技术,基于原生3D VAE,实现了16倍的空间压缩,从而能够高效、可扩展地生成高达1536³分辨率的PBR纹理资产。
主要特点
1. 高质量、高分辨率、高效率
该模型使用标准的DiT架构,即可生成保真度极高的全纹理3D资产,且速度惊人。
- 3秒 (2秒形状+1秒材质) → 512³分辨率
- 17秒 (10秒+7秒) → 1024³分辨率
- 60秒 (35秒+25秒) → 1536³分辨率
注:测试基于NVIDIA H100 GPU。总时间为形状生成与材质生成之和。
其紧凑的潜在表示,在保真度和效率之间取得了突破性平衡。
2. 处理任意拓扑结构
传统方法常受限于流形表面。T-RELLIS .2能够稳健处理各种复杂几何结构:
- ✔ 开放式表面 (如布料、纸张)
- ✔ 非流形几何 (多个面共享一条边)
- ✔ 内部结构 (封闭物体内的细节)
这打破了等值面场的限制,极大地扩展了可生成的模型类型。

3. 丰富的材质建模
模型能够为任意表面生成基于物理的渲染 (PBR) 属性,包括:
- 基础色
- 粗糙度
- 金属度
- 不透明度 (Alpha通道)
这意味着生成的资产可直接用于游戏引擎或渲染器中进行逼真的打光和渲染。

4. 极简的资产处理
其数据处理流程非常简单,实现了近乎“即时”的转换,无需复杂的渲染或优化步骤。
- 编码 (纹理网格 → O-体素): 单CPU < 10秒
- 解码 (O-体素 → 纹理网格): CUDA加速下 < 100毫秒
实际应用展示
图像到3D资产生成
从简单的草图到复杂的场景,模型都能胜任,涵盖多种类型:
- 详细物体、有机形态、特征性物品
- 完整场景、薄壁几何体、透明物体
- 硬表面、开放表面、内部结构、丰富材质



3D资产重建
模型还支持从单张或多张图片进行高质量的3D重建。
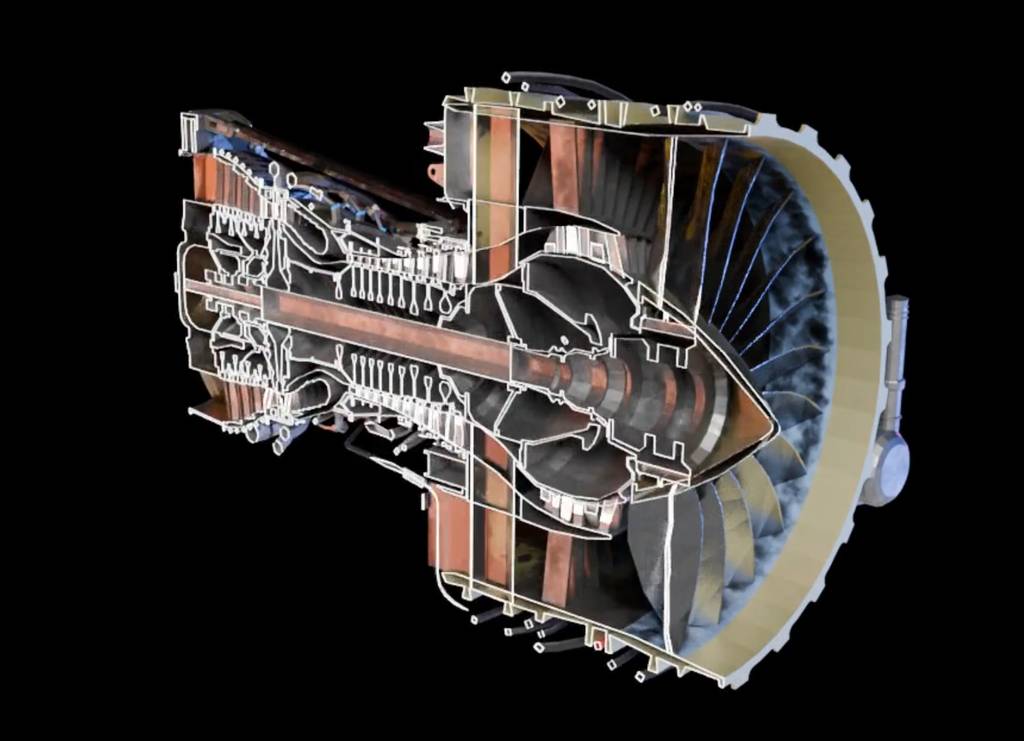

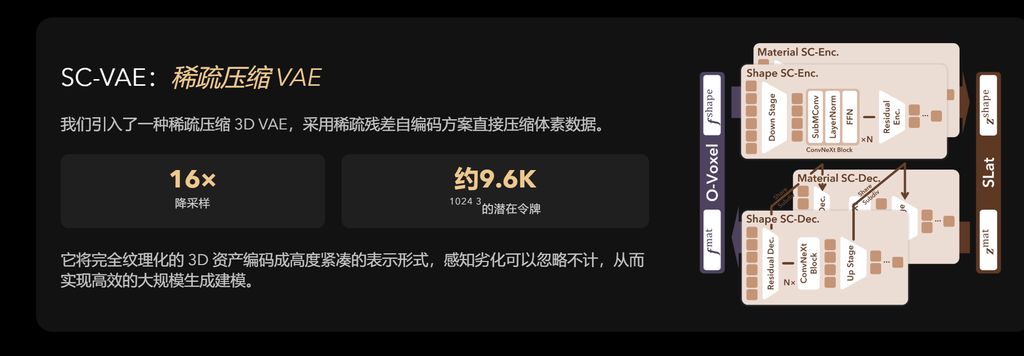
技术核心:创新的流程
T-RELLIS .2的工作流程始于一个即时双向转换步骤,将3D网格转换为一种名为 O-Voxel 的新颖表示形式。随后,一个稀疏压缩VAE 将这些体素编码到一个紧凑、结构化的潜在空间中,为后续的生成或重建提供基础。


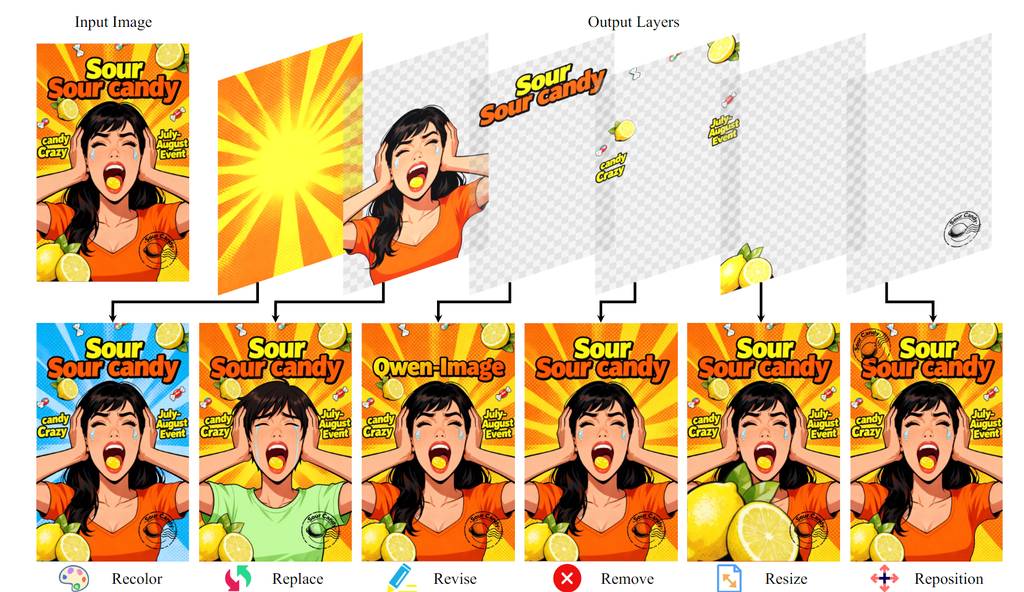
二、Qwen-Image-Layered:实现图像的“原生可编辑性” via 图层分解
如果说T-RELLIS .2拓展了设计的维度,那么通义千问团队的 Qwen-Image-Layered 则是在深化平面设计的编辑逻辑。当前的AI图像编辑工具常因光栅图像的“像素纠缠”问题而导致编辑不一致。而专业设计软件(如Photoshop)采用图层表示,允许独立编辑。
受此启发,Qwen-Image-Layered 提出了一种端到端的扩散模型,能够将单张RGB图片智能分解为多个语义解耦的RGBA图层,从而实现“原生可编辑性”——每个图层都可以被独立操控而不影响其他内容。
技术亮点
为了实现可变长度的图层分解,研究团队引入了三个关键组件:
- RGBA-VAE:统一RGB和RGBA图像的潜在表示,解决了之前方法中因使用不同VAE导致的输入输出分布差距问题。
- VLD-MMDiT架构:一种能够分解可变数量图像层的新型架构。
- 多阶段训练策略:将预训练的图像生成模型适配为多层图像分解器。
此外,为了解决高质量多层训练数据稀缺的问题,团队构建了一个从Photoshop文档 (PSD) 中提取和标注多层图像的自动化流程。
效果与优势
实验表明,该方法在分解质量上显著超越了现有方案,为保持一致的图像编辑建立了新范式。
定量比较:在Crello数据集上的“图像转多层RGBA”任务中,Qwen-Image-Layered在RGB重建误差和Alpha通道预测精度(Alpha soft IoU)上均达到最佳。
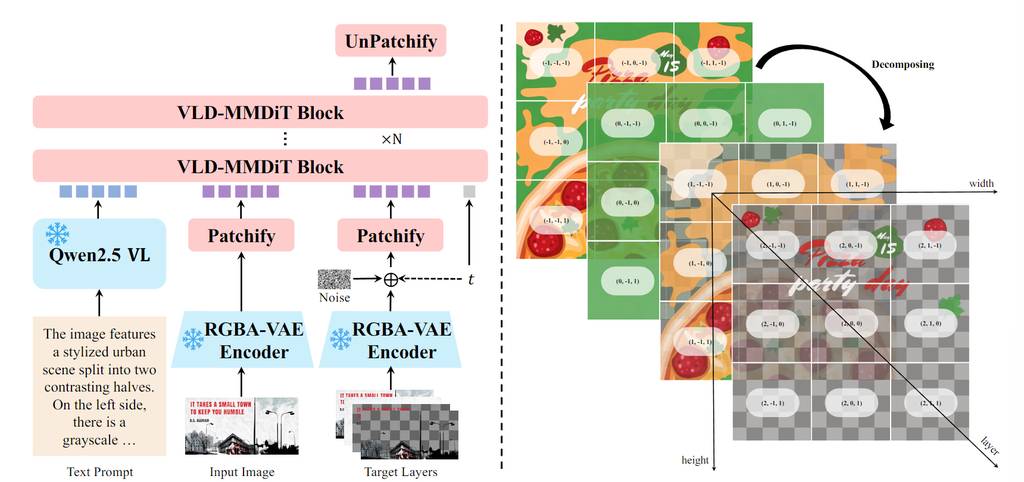 表1:在Crello数据集上的定量对比
表1:在Crello数据集上的定量对比

定性展示:模型能准确地将前景人物、背景、装饰元素等分离到不同图层,并生成精确的透明度通道。

项目开源:代码与模型已在GitHub发布:https://github.com/QwenLM/QwenImage-Layered
写在最后
对于设计师而言,这两项技术指向了一个更智能、更流畅的未来:
- T-RELLIS .2 极大地降低了3D内容创作的门槛和时间成本,让概念验证、原型制作、资产创建变得前所未有的快捷。它不仅是建模工具,更是连接2D创意与3D世界的“桥梁”。
- Qwen-Image-Layered 则将专业设计软件的图层思维注入AI,让AI生成的图像不再是一个“黑箱”或“整体”,而是像我们亲手制作的设计稿一样,具备可拆分、可调整的灵活性。这为后续的精细化编辑、风格迁移、内容重组打开了大门。
它们共同预示着,AI正在从“执行指令”向“理解结构”进化。未来的设计工具,或许会是一个能理解你的草图意图并构建三维场景,同时能将任何参考图自动分层供你自由改编的智能工作台。保持关注,积极尝试,这些技术很快就会从论文走进你的设计软件。
更多 AI 前沿技术与设计灵感,欢迎关注「设计小站」公众号(ID:sjxz00),一起探索科技与设计的融合创新。